Еще на VMworld 2014 компания VMware анонсировала технологию VMware Project Fargo (которая также называлась VM Fork), позволяющую очень быстро сделать работающую копию работающей виртуальной машины на платформе VMware vSphere.
Суть технологии VMFork такова, что "на лету" создается клон виртуальной машины (VMX-файл, процесс в памяти), который начинает использовать ту же память (Shared memory), что и родительская ВМ. При этом дочерняя ВМ в общую память писать не может, а для записи собственных данных используется выделенная область памяти. Для дисков аналогично - с использованием технологии Copy-on-write в дельта-диск дочерней ВМ пишутся отличия от базового диска родительской ВМ:
В процессе работы VMFork происходит кратковременное "подвешивание" родительской ВМ (quiescence) с помощью технологии "fast suspend resume" (FSR), после чего дочерняя ВМ "отцепляется" от родительской - происходит реконфигурация машины, включающая в себя назначение нового MAC-адреса, получение нового UUID и другое. При этом ВМ шарят общие ресурсы на чтение и имеют свои уникальные области на запись - это очень удешевляет стоимость ресурсов в перерасчете на одну ВМ на хосте.
После выхода новой версии платформы виртуализации настольных ПК VMware Horizon 7 технология VMFork была переименована в Instant Clone и стала доступна для использования в производственной среде. Помимо удешевления стоимости ресурсов для размещения виртуальных машин, Instant Clone имеет еще несколько преимуществ - это делает развертывание виртуальных машин более гибким и быстрым. Ниже мы рассмотрим особенности этих процессов.
В сочетании с технологией доставки приложений через подключаемые виртуальные диски VMware App Volumes 3.0 и средством управления окружениями User Environment Manager, эти возможности позволяют пользователям получить мгновенный доступ к своим данным, при этом рабочая машина пользователя не "загрязняется" ненужными устанавливаемыми программами и распухающими ветками реестра. Это все позволяет собрать десктоп пользователя на лету из полностью кастомизируемых и доставляемых по требованию "кирпичиков".
Давайте посмотрим, насколько Instant Clone упрощает цикл развертывания новых настольных ПК. Вот так выглядит развертывание связанных клонов (Linked Clones) в инфраструктуре VMware View Composer:
Клонирование виртуального ПК из реплики мастер-образа
Реконфигурация нового ПК
Включение ВМ
Кастомизация машины
Создание контрольной точки нового ПК (checkpoint)
Включение ВМ
Логин пользователя
С использованием Instant Clone процесс заметно упрощается:
Создание копии ВМ в памяти средствами VMFork
Кастомизация машины
Включение ВМ
Логин пользователя
Для администратора виртуальных ПК в пулах Instant Clone удобны тем, что таким десктопам не требуются операции Refresh, Recompose и Rebalance. Ведь после выхода пользователя из ПК его десктоп уничтожается, а перестраивать связанные клоны не требуется. Изменения базового образа проходят "на лету" в течение рабочего дня, а при следующем логине пользователь получает уже обновленные приложения. Также есть возможность принудительного перелогина пользователя для обновления компонентов виртуального ПК (например, фикс в подсистеме безопасности).
Также отпадает необходимость в использовании технологии Content-Based Read Cache (CBRC), ведь виртуальные ПК Instant Clone живут недолго, постоянно выгружаются из памяти при выходе пользователя, и нет нужды прогревать кэш их блоками в памяти, а вот для мастер-ВМ и реплик CBRC вполне себе используется.
Кроме того, теперь не нужны операции wipe и shrink для виртуальных дисков SEsparse, которые позволяют возвращать место на растущем диске для связанных клонов. Виртуальные машины Instant Clone живут недолго, а при их уничтожении дисковое пространство их дельта-дисков возвращается в общий пул пространства хранения.
Ну и в отличие от View Composer, технология Instant Clone не требует наличия и поддержки базы данных для операций с виртуальными ПК, что существенно упрощает обслуживание инфраструктуры виртуальных десктопов.
Многие думают, что пулы Instant Clone трудно создавать, настраивать и поддерживать. Это не так, все делается в несколько простых шагов:
Создаем родительскую виртуальную машину, устанавливаем в ней Windows, оптимизируем ее и активируем лицензионным ключом.
Устанавливаем VMware Tools.
Устанавливаем Horizon Agent и отмечаем фичу Instant Clone для установки.
При добавлении нового пула виртуальных ПК типа Automated/Floating отмечаем Instant Linked Clones.
Помимо того, что с Instant Clone процесс проходит меньшее количество шагов, уменьшается и нагрузка на различные компоненты виртуальной инфраструктуры - меньше операций ввода-вывода, быстрее происходит процесс создания мгновенной копии (скорее освобождаются системные ресурсы), меньше объем взаимодействий с сервером vCenter, а дисковое пространство высвобождается сразу после окончания использования виртуального ПК.
Давайте посмотрим, насколько быстрее это работает на тестах. Развертывание связанных клонов View Composer типовой конфигурации (2 vCPU, 2 GB memory, Windows 7, Office 2010, Adobe 11, 7-Zip, Java) на 15 хост-серверах с использованием HDD-дисков занимает где-то 150-200 минут. А то же самое развертывание 1000 виртуальных машин на базе Instant Clone занимает лишь 25-30 минут. То есть скорость получения новой инфраструктуры десктопов по запросу возрастает в 5-7 раз.
При этом не особо-то и растет нагрузка на сервер VMware vCenter. Поначалу, конечно же, возникает пиковая нагрузка на vCenter при операциях в оперативной памяти с мгновенными копиями ВМ, но в итоге средняя загрузка практически такая же, как и при использовании View Composer - ведь не нужно проходить цикл включения (2 раза) и реконфигурации виртуальной машины (3-4 раза), как это происходит у Composer.
В итоге, можно сказать, что в определенных случаях Instant Clone - это лучшее решение с точки зрения быстродействия и производительности. Когда виртуальную машину нужно получить как можно быстрее, а пользователю после окончания работы она не нужна в том виде, в котором он ее оставил - мгновенные копии позволят ускорить процесс в несколько раз. Примером такого варианта использования может служить колл-центр, где оператор использует виртуальный десктоп для решения определенной задачи технической поддержки, после чего от разлогинивается, уничтожая ненужную в данный момент сущность - свой виртуальный десктоп.
Есть пара интересных постов, на базе которых мы попробуем вкратце описать поведение кластера VMware Virtual SAN в случае, если при развертывании виртуальной машины кластер не способен обеспечить требуемые политики хранилищ (Storage Policies).
1. Обычный кластер Virtual SAN.
Если при развертывании новой ВМ в кластере VSAN невозможно обеспечить требуемые политики хранилищ (например, не хватает места для создания зеркалируемых объектов реплик), а именно:
то виртуальная машина не сможет быть развернута в кластере. Но есть такая настройка Force Provisioning для VM Storage Policy, которая позволяет игнорировать указанные 3 параметра при развертывании новой ВМ в кластере.
Однако надо понимать, что при использовании Force Provisioning происходит не понижение требований кластера к хранилищу виртуальной машины (например, вместо FTT=2 можно было бы проверить FTT=1), а использование следующих параметров:
NumberOfFailuresToTolerate = 0
NumberOfDiskStripesPerObject = 1
FlashReadCacheReservation = 0
То есть нужно просто аллоцировать место под виртуальную машину, совершенно без соблюдения требований к дублированию данных и резервированию кэша.
Но кластер Virtual SAN имеет еще одну специфическую черту - если вы использовали Force Provisioning при недостатке дисковых ресурсов, то когда они освободятся, для хранилища машины будут сделаны реплики дисковых объектов и прочие операции, чтобы она все-таки соответствовала требуемым политикам хранилищ. Администраторам надо иметь эту особенность в виду.
И еще один момент - так как в случае Force Provisioning может храниться только одна копия дисковых объектов, то, например, если при переводе хоста в режим Maintenance Mode случится какой-нибудь сбой с его хранилищем - реально можно потерять эту машину целиком. Делайте бэкап и, по-возможности, не используйте Force Provisioning - старайтесь соблюдать политики хранилищ хотя бы на уровне FTT=1.
2. Растянутый кластер (Stretched Cluster).
В случае растянутого кластера появляется еще один компонент - Witness Appliance, следящий за ситуацией Split Brain, которая может появиться между площадками. Если вырубить этот виртуальный модуль и попытаться включить виртуальную машину или создать новую ВМ, то кластер Virtual SAN (несмотря на то, что он Failed и политика хранилищ не соблюдена) позволит это сделать, правда будет ругаться, что машина не соответствует текущим политикам хранилищ:
В остальном растянутый кластер ведет себя по отношению к Force Provisioning так же, как и обычный.
Некоторые из вас знают, что для поиска и решения проблем в виртуальной инфраструктуры, среди прочих интерфейсов командной строки, есть такой инструмент, как Ruby vSphere Console (RVC).
Используется она достаточно редко, но ниже мы покажем пример ее использования на базе вот этой заметки от Кормака Хогана.
Чтобы запустить Ruby vSphere Console, нужно набрать в командной строке ESXi команду в следующем формате:
rvc [options] [username[:password]@]hostname
Например:
# rvc administrator:vmware@192.168.1.100
После этого появится приглашение ко вводу различных команд:
login as: root
VMware vCenter Server Appliance
administrator@192.168.1.100's password:
Last login: Thu Jul 17 22:29:15 UTC 2014 from 10.113.230.172 on ssh
Last failed login: Fri Jul 18 06:31:16 UTC 2014 from 192.168.1.20 on ssh:notty
There was 1 failed login attempt since the last successful login.
Last login: Fri Jul 18 06:31:35 2014 from 192.168.1.20
vcsa:~ # rvc administrator:vmware@192.168.1.100
0 /
1 192.168.1.100/
Их можно выполнять в рамках следующих пространств имен (namespaces):
Во второй снизу строчке мы видим пространство имен VSAN, относящееся к кластерам хранилищ Virtual SAN. Давайте посмотрим на решение одной проблемки с его помощью.
Допустим, вы увидели в кластере VSAN следующую ошибку в разделе Component Metadata Health:
Invalid state
Согласно вот этой статье KB 2108690, эта ошибка может относиться к физической проблеме с диском - когда процесс выделения физических блоков при сбрасывании их из кэша на диск идет очень медленно. Эта ошибка может свидетельствовать просто о высокой нагрузке на диск, в этом случае она уходит при спаде нагрузки. Но если она повторяется при малой нагрузке - значит с диском явно что-то не так.
В столбце "Component" указан component UUID диска, с которым возникла проблема - но как узнать, на каком хранилище он расположен, в консоли vSphere Web Client? Для этого мы и возьмем Ruby vSphere Console, а именно команду vsan.cmmds_find:
Давно мы не публиковали таблицу сравнения изданий VMware vSphere, а ведь в версии vSphere 6.0 много что изменилось, поэтому иногда полезно взглянуть на таблицу ниже. Кроме того, помните, что с 30 июня колонок в таблице станет на одну меньше - издание vSphere Enterprise снимается с продаж.
Возможность / Издание VMware vSphere
Hypervisor 6 (бесплатный ESXi)
vSphere Essentials 6
vSphere Essentials Plus 6
vSphere Standard 6
vSphere Enterprise 6.0 - (снимается с продаж 30 июня 2016 года
Какое-то время назад мы писали о функции Data Locality, которая есть в решении для создания отказоустойчивых кластеров VMware Virtual SAN. Каждый раз, когда виртуальная машина читает данные с хранилища, они сохраняются в кэше (Read Cache) на SSD-накопителе, и эти данные могут быть востребованы очень быстро. Но в рамках растянутого кластера (vSphere Stretched Cluster) с высокой скоростью доступа к данным по сети передачи данных, возможно, фича Site / Data Locality вам не понадобится. Вот по какой причине.
Если ваши виртуальные машины часто переезжают с хоста на хост ESXi, при этом сами хосты географически разнесены в рамках VSAN Fault Domains, например, по одному зданию географически, то срабатывает функция Site Locality, которая требует, чтобы кэш на чтение располагался на том же узле/сайте, что и сами дисковые объекты машины. Это отнимает время на прогрев кэша хоста ESXi на новом месте для машины, а вот в скорости в итоге особой прибавки не дает, особенно, если у вас высокоскоростное соединение для всех серверов в рамках здания.
В этом случае Site Locality лучше отключить и не прогревать кэш каждый раз при миграциях в рамкха растянутого кластера с высокой пропускной способностью сети. Сначала запросим значение Site Locality:
Компания VMware в своем блоге, посвященном продуктам линейки VMware vSphere, представила интереснейшее доказательство, что кластер VMware Virtual SAN дает надежность "шесть девяток", то есть доступность данных 99,9999% времени в году. А это меньше, чем 32 секунды простоя в год.
Бесспорно, приведенное ниже "доказательство" основано на множестве допущений, поэтому заявление о шести девятках является несколько популистским. С моей точки зрения, гораздо более вероятно, что админ с бодуна не туда нажмет, или, например, в команде vmkfstools укажет не тот LUN и снесет все виртуальные машины на томе VMFS (привет, Антон!), чем откажет оборудование с дублированием компонентов. Но все же, рассмотрим это доказательство ниже.
Прежде всего, введем 2 понятия:
AFR – Annualized Failure Rate, то есть вероятность отказа в год (носителя данных или другого компонента), выраженная в процентах.
MTBF – Mean Time Between Failures (среднее время между отказами). Это время в часах.
Эти 2 величины взаимосвязаны и выражаются одна через другую в соответствии с формулой:
AFR = 1/(MTBF/8760) * 100%
Обычно, как HDD, так и SSD накопители, имеют AFR от 0.87% до 0.44%, что дает от 1 000 000 до 2 000 000 часов MTBF. Далее для примера берут диск 10K HDD от Seagate (популярная модель ST1200MM0088), для которой AFR равен 0.44% (см. вторую страницу даташита) или 2 миллиона часов в понятии MTBF. Ну и взяли популярный SSD Intel 3710 для целей кэширования, который также имеет MTBF на 2 миллиона часов.
Для того, чтобы вычислить время доступности данных на таких накопителях, нужно понимать время, которое необходимо для восстановления бэкапа на новый накопитель в случае сбоя. По консервативным оценкам - это 24 часа. Таким образом, доступность данных будет равна:
2 000 000/ (2 000 000 + 24) = 0,99998
То есть, 4 девятки. Но диск - это еще не весь сервис. Есть еще надежность дискового контроллера, самого хост-сервера и стойки в целом (по питанию). VMware запросила данные у производителей и получила следующие параметры доступности:
Вот, доступность уже 3 девятки, что эквивалентно 8,76 часов простоя в год. Не так плохо, но это слишком оптимистичные значения - на деле есть прочие факторы, влияющие на доступность, поэтому уберем последнюю цифру из долей для доступности каждого из компонентов:
Получается 2 девятки, а это 3,65 дня простоя в год, что уже довольно критично для многих бизнесов.
Ну а теперь применим технологию VMware Virtual SAN, которая дублирует данные на уровне виртуальных машин и отдельных виртуальных дисков. Если мы используем параметр FTT (Numbers of failures to tolerate) равный 1, что подразумевает хранение одной реплики данных, то вероятность недоступности хранилища Virtual SAN данных будет равна вероятности отказа 2-х хранилищ одновременно, то есть:
(1-0.997)^2 = 0.00000528
Ну а доступность в данном случае равна:
1-0.00000528 = 0.999994
То есть, уже 5 девяток. Но это доступность для одного объекта VSAN, а отдельная виртуальная машина обычно имеет несколько объектов, допустим, 10. Тогда ее доступность будет равна:
0.999994^10 = 0.99994
В итоге, 4 девятки. Это 52,56 минуты простоя в год. В зависимости от того, сколько объектов у вас будет на одну ВМ, вы будете иметь доступность от 4 до 5 девяток.
А теперь возьмем FTT=2, то есть конфигурацию, когда имеется 2 дополнительных копии данных для каждого объекта в кластере Virtual SAN. В этом случае вероятность полного отказа всех трех копий данных:
(1-0.997)^3 = 0.00000001214
А доступность для ВМ с десятью объектами:
0.999999988^10 = 0.999999879
То есть, те самые 6 девяток, о которых говорится на слайде. Конечно, все это допущения, фантазии и игра с вероятностями, но читать это все равно интересно. Еще более интересно то, что оригинал этой статьи написала женщина)
Таги: VMware, Virtual SAN, HA, VSAN, Enterprise, Blog, Availability, Storage
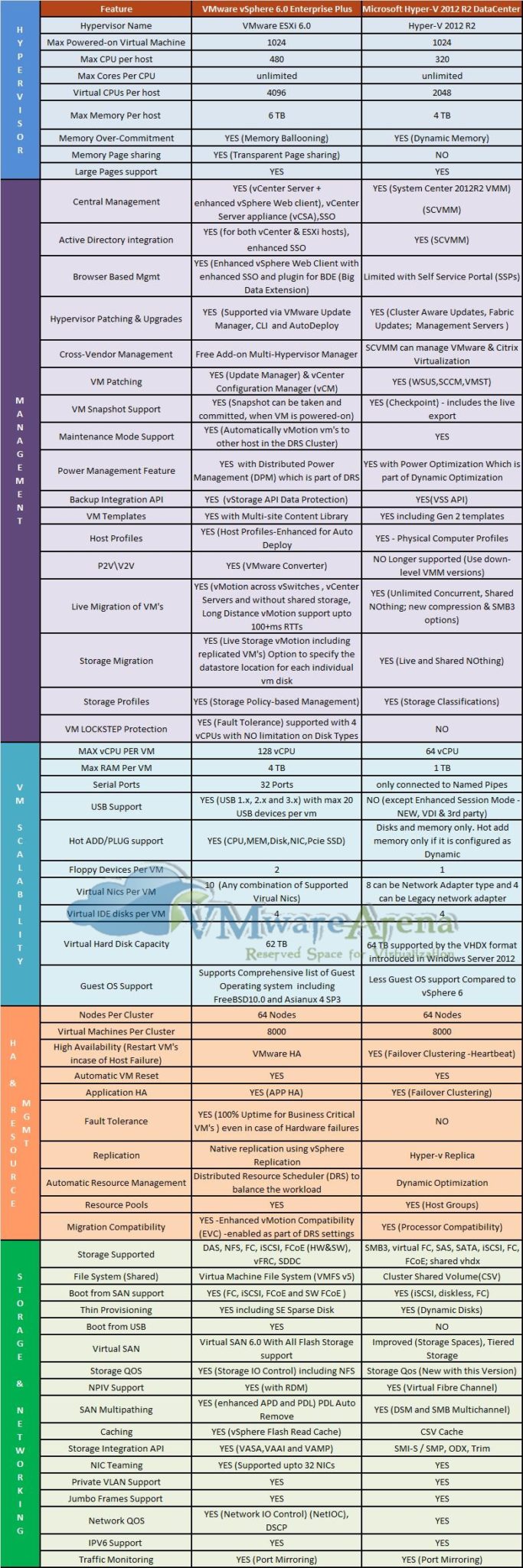
Не так давно на сайте VMwareArena появилось очередное сравнение VMware vSphere (в издании Enterprise Plus) и Microsoft Hyper-V в Windows Server 2012 R2 Datacenter Edition, которое включает в себя самую актуальную информацию о возможностях обеих платформ.
Мы адаптировали это сравнение в виде таблицы и представляем вашему вниманию ниже:
Группа возможностей
Возможность
VMware vSphere 6
Enterprise Plus
Microsoft Hyper-V в Windows Server 2012 R2 Datacenter Edition
Возможности гипервизора
Версия гипервизора
VMware ESXi 6.0
Hyper-V 2012 R2
Максимальное число запущенных виртуальных машин
1024
1024
Максимальное число процессоров (CPU) на хост-сервер
480
320
Число ядер на процессор хоста
Не ограничено
Не ограничено
Максимальное число виртуальных процессоров (vCPU) на хост-сервер
4096
2048
Максимальный объем памяти (RAM) на хост-сервер
6 ТБ
4 ТБ
Техники Memory overcommitment (динамическое перераспределение памяти между машинами)
Memory ballooning
Dynamic Memory
Техники дедупликации страниц памяти
Transparent page sharing
Нет
Поддержка больших страниц памяти (Large Memory Pages)
Да
Да
Управление платформой
Централизованное управление
vCenter Server + vSphere Client + vSphere Web Client, а также виртуальный модуль vCenter Server Appliance (vCSA)
System Center Virtual Machine Manager (SC VMM)
Интеграция с Active Directory
Да, как для vCenter, так и для ESXi-хостов через расширенный механизм SSO
Да (через SC VMM)
Поддержка снапшотов (VM Snapshot)
Да, снапшоты могут быть сделаны и удалены для работающих виртуальных машин
Да, технология Checkpoint, включая функции live export
Управление через браузер (тонкий клиент)
Да, полнофункциональный vSphere Web Client
Ограниченное, через Self Service Portal
Обновления хост-серверов / гипервизора
Да, через VMware Update Manager (VUM), Auto Deploy и CLI
Да - Cluster Aware Updates, Fabric Updates, Management Servers
Управление сторонними гипервизорами
Да, бесплатный аддон Multi-Hypervisor Manager
Да, управление VMware vCenter и Citrix XenCenter поддерживается в SC VMM
Обновление (патчинг) виртуальных машин
Да, через VMware Update Manager (VUM) и vCenter Configuration Manager (vCM)
Да (WSUS, SCCM, VMST)
Режим обслуживания (Maintenance Mode)
Да, горячая миграция ВМ в кластере DRS на другие хосты
Да
Динамическое управление питанием
Да, функции Distributed Power Management в составе DRS
Да, функции Power Optimization в составе Dynamic Optimization
API для решений резервного копирования
Да, vStorage API for Data Protection
Да, VSS API
Шаблоны виртуальных машин (VM Templates)
Да + Multi-site content library
Да, включая шаблоны Gen2
Профили настройки хостов (Host Profiles)
Да, расширенные функции host profiles и интеграция с Auto Deploy
Да, функции Physical Computer Profiles
Решение по миграции физических серверов в виртуальные машины
Да, VMware vCenter Converter
Нет, больше не поддерживается
Горячая миграция виртуальных машин
Да, vMotion между хостами, между датацентрами с разными vCenter, Long Distance vMotion (100 ms RTT), возможна без общего хранилища
Да, возможна без общего хранилища (Shared Nothing), поддержка компрессии и SMB3, неограниченное число одновременных миграций
Горячая миграция хранилищ ВМ
Да, Storage vMotion, возможность указать размещение отдельных виртуальных дисков машины
Да
Профили хранилищ
Да, Storage policy-based management
Да, Storage Classifications
Кластер непрерывной доступности ВМ
Да, Fault Tolerance с поддержкой до 4 процессоров ВМ, поддержка различных типов дисков, технология vLockstep
Нет
Конфигурации виртуальных машин
Виртуальных процессоров на ВМ
128 vCPU
64 vCPU
Память на одну ВМ
4 ТБ
1 ТБ
Последовательных портов (serial ports)
32
Только присоединение к named pipes
Поддержка USB
До 20 на одну машину (версии 1,2 и 3)
Нет (за исключением Enhanced Session Mode)
Горячее добавление устройств
(CPU/Memory/Disk/NIC/PCIe SSD)
Только диск и память (память только, если настроена функция Dynamic memory)
Диски, растущие по мере наполнения данными (thin provisioning)
Да (thin disk и se sparse)
Да, Dynamic disks
Поддержка Boot from USB
Да
Нет
Хранилища на базе локальных дисков серверов
VMware Virtual SAN 6.0 с поддержкой конфигураций All Flash
Storage Spaces, Tiered Storage
Уровни обслуживания для подсистемы ввода-вывода
Да, Storage IO Control (работает и для NFS)
Да, Storage QoS
Поддержка NPIV
Да (для RDM-устройств)
Да (Virtual Fibre Channel)
Поддержка доступа по нескольким путям (multipathing)
Да, включая расширенную поддержку статусов APD и PDL
Да (DSM и SMB Multichannel)
Техники кэширования
Да, vSphere Flash Read Cache
Да, CSV Cache
API для интеграции с хранилищами
Да, широкий спектр VASA+VAAI+VAMP
Да, SMI-S / SMP, ODX, Trim
Поддержка NIC Teaming
Да, до 32 адаптеров
Да
Поддержка Private VLAN
Да
Да
Поддержка Jumbo Frames
Да
Да
Поддержка Network QoS
Да, NetIOC (Network IO Control), DSCP
Да
Поддержка IPv6
Да
Да
Мониторинг трафика
Да, Port mirroring
Да, Port mirroring
Подводя итог, скажем, что нужно смотреть не только на состав функций той или иной платформы виртуализации, но и необходимо изучить, как именно эти функции реализованы, так как не всегда реализация какой-то возможности позволит вам использовать ее в производственной среде ввиду различных ограничений. Кроме того, обязательно нужно смотреть, какие функции предоставляются другими продуктами от данного вендора, и способны ли они дополнить отсутствующие возможности (а также сколько это стоит). В общем, как всегда - дьявол в деталях.
Таги: VMware, vSphere, Hyper-V, Microsoft, Сравнение, ESXi, Windows, Server
Компания VMware выпустила очень познавательный документ "An overview of VMware Virtual SAN caching algorithms", который может оказаться полезным всем тем, кто интересуется решением для создания программных хранилищ под виртуальные машины - VMware Virtual SAN. В документе описан механизм работы кэширования, который опирается на производительные SSD-диски в гибридной конфигурации серверов ESXi (то есть, SSD+HDD).
SSD-диски используются как Performance tier для каждой дисковой группы, то есть как ярус производительности, который преимущественно предназначен для обеспечения работы механизма кэширования на чтение (Read cache, RC). По умолчанию для этих целей используется 70% емкости SSD-накопителей, что экспериментально было определено компанией VMware как оптимальное соотношение.
SSD-диски значительно более производительны в плане IOPS (тысячи и десятки тысяч операций в секунду), поэтому их удобно использовать для кэширования. Это выгодно и с экономической точки зрения (доллары на IOPS), об этом в документе есть наглядная табличка:
То есть, вы можете купить диск SSD Intel S3700 на 100 ГБ за $200, который может выдавать до 45 000 IOPS, а это где-то $0,004 за IOPS. С другой же стороны, можно купить за те же $200 диск от Seagate на 1 ТБ, который будет выдавать всего 100 IOPS, что составит $2 на один IOPS.
Кэш на чтение (RC) логически разделен на "cache lines" емкостью 1 МБ. Это такая единица информации при работе с кэшем - именно такой минимальный объем на чтение и резервирование данных в памяти используется. Эта цифра была высчитана экспериментальным путем в исследовании нагрузок на дисковую подсистему в реальном мире, которое VMware предпочитает не раскрывать. Кстати, такой же величины объем блока в файловой системе VMFS 5.x.
Помимо обслуживания кэша на SSD, сервер VMware ESXi использует небольшой объем оперативной памяти (RAM) для поддержки горячего кэша обслуживания этих самых cache lines. Он содержит несколько самых последних использованных cache lines, а его объем зависит от доступной памяти в системе.
Также в памяти хранятся некоторые метаданные, включая логические адреса cache lines, валидные и невалидные регионы кэша, информация о сроке хранения данных в кэше и прочее. Все эти данные постоянно хранятся в памяти в сжатом виде и никогда не попадают в своп. При перезагрузке или выключении/включении хоста кэш нужно прогревать заново.
Итак, как именно работает кэширование на SSD в VMware Virtual SAN:
1. Когда операция чтения приходит к Virtual SAN, сразу же включается механизм определения того, находятся ли соответствующие данные в кэше или нет. При этом запрашиваемые данные за одну операцию могут быть больше одной cache line.
2. Если данные или их часть не находятся в RC, то для них резервируется буфер нужного объема с гранулярностью 1 МБ (под нужное количество cache lines).
3. Новые аллоцированные cache lines вытесняют из кэша старые в соответствии с алгоритмом Adaptive Replacement Cache (ARC), который был лицензирован VMware у IBM.
4. В случае промаха кэша каждое чтение одной cache line с HDD разбивается на чанки размером 64 КБ (этот размер тоже был определен экспериментально в ходе исследований). Это сделано для того, чтобы не забивать очередь на чтение с HDD "жирной" операцией чтения в 1 МБ, которая бы затормозила общий процесс ввода-вывода на диск.
5. В общем случае, одна операция чтения запрашивает лишь часть данных одной cache line, а первыми читаются именно нужные 64 КБ чанки с HDD-диска от этой cache line.
6. Запрошенные с HDD-диска данные сразу отдаются к подсистеме вывода и направляются туда, откуда их запросили, а уже потом в асинхронном режиме они попадают в соответствующие cache lines кэша и под каждую из них выделяется буфер 1 МБ в памяти. Таким образом устраняются потенциальные затыки в производительности.
В документе описаны также и механики работы кэша на запись (Write cache), для которого используется техника write-back, а также рассматриваются All Flash конфигурации. Читайте - это интересно!
Мы уже писали про издание технического характера VMware Technical Journal (VMTJ), которое представляет собой периодический журнал о различного рода проблемах, которые рассматриваются научными и инженерными сотрудниками компании VMware. Некоторое время назад этот проект переехал на портал VMware Labs, посвященный различного рода разработкам, облегчающим пользователям работу с продуктами в сфере виртуализации на платформах VMware. Также там есть и ресурсы, касающиеся VMware Academic Program.
Журнал VMTJ выходит два раза в год - зимой и летом, сейчас пока доступен только зимний номер этого года (69 страниц), но к концу лета должен подоспеть и следующий.
Статьи больше похожи на научные труды - это не посты о том, как какой-нибудь VMware NSX настраивать, а более глубокие и абстрактные исследования:
FlashStream: A Multitiered Storage Architecture in Data Centers for Adaptive HTTP Streaming
Reducing Cache-Associated Context-Switch Performance Penalty Using Elastic Time Slicing
The Role of Social Graph in Content Discovery Within Enterprise Social Networking
NoETL: ETL Code Generation for a Dimensional-Data Warehouse
A Framework for Secure Offline Authentication and Key Exchange Between Mobile Devices
Just-in-Time Desktops and the Evolution of VDI
Connectivity and Collaboration in VMware vCloud Suite
Directions in Mobile Enterprise Connectivity
В конце каждой статьи идет внушительный список использованной литературы. Всего с 2012 года было выпущено 6 неморов журнала VMTJ. Вот ссылки на предыдущие выпуски:
Недавно компания EMC сделала доступным виртуальный модуль (Virtial Appliance) vVNX community edition, представляющий собой готовую ВМ в формате OVF, с помощью которой можно организовать общее хранилище для других виртуальных машин.
Видеообзор vVNX с EMC World:
Сам продукт фактически представляет собой виртуальный VNXe 3200. Для его работы вам потребуется:
VMware vSphere 5.5 или более поздняя версия
Сетевая инфраструктура с двумя адаптерами 1 GbE или 10 GbE
Replication – возможность асинхронной репликации на уровне блоков для локальных и удаленных инстансов vVNX. Также поддерживается репликация между vVNX и настоящим VNXe 3200.
Unified Snapshots – поддержка технологии снапшотов как на уровне блоков, так и на уровне файлов. Для этого используется технология Redirect on Write (ROW).
VMware Integration – vVNX предоставляет несколько механизмов интеграции с платформой VMware vSphere, таких как VASA, VAI и VAAI. Это позволяет производить мониторинг хранилищ vVNX из клиента vSphere, создавать хранилища из Unisphere, а также использовать техники compute offloading.
Flexible File Access – к хранилищам можно предоставить доступ через CIFS или NFS. Причем оба протокола можно использовать для одной файловой системы. Также можно использовать FTP/SFTP-доступ.
Для виртуальной машины с Virtual VNX потребуется 2 vCPU, 12 ГБ оперативной памяти и до 4 ТБ хранилища для виртуальных дисков.
Также кое-где на сайте EMC заявляется, что vVNX поддерживает технологию Virtual Volumes (VVOls) от VMware, что позволяет потестировать эти хранилища, не имея физического хранилища с поддержкой этого механизма. Это неверно. Поддержка VVols в vVNX будет добавлена только в третьем квартале этого года (пруф).
Пока можно посмотреть вот это видео на эту тему:
Скачать vVNX и получить бесплатную лицензию к нему можно по этой ссылке. Материалы сообщества, касающиеся vVNX объединены по этой ссылке, а вот тут можно посмотреть видео развертывания продукта и скачать гайд по установке. Ну и вот тут вот доступен FAQ.
Как многие из вас знают, одной из новых возможностей VMware vSphere 6.0 в плане хранилищ стала новая архитектура Virtual Volumes (VVols). VVols - это низкоуровневое хранилище для виртуальных машин, с которым позволены операции на уровне массива по аналогии с теми, которые сегодня доступны для традиционных LUN - например, снапшоты дискового уровня, репликация и прочее. Тома VVols создаются на дисковом массиве при обращении платформы к новой виртуальной машине (создание, клонирование или снапшот). Для каждой виртуальной машины и ее файлов, которые вы видите в папке с ВМ, создается отдельный VVol.
Между тем, поскольку технология VVol на сегодняшний день находится в первой своей релизной версии, а продуктов у VMware очень много, на сайте VMware появился список продуктов (в пункте 1 выберите Virtual Volumes), с которыми VVols работают, и тех, где поддержка еще не заявляена.
В целом можно сказать, что внедрять VVols в производственной среде полноценно пока рано, первая версия технологии предназначена скорее для тестирования и пробной эксплуатации с отдельными системами предприятия.
Продукты и технологии, которые поддерживают Virtual Volumes (VVols):
Продукты VMware:
VMware vSphere 6.0.
VMware vRealize Automation 6.2.
VMware Horizon 6.1.
VMware vSphere Replication 6.0
VMware NSX for vSphere 6.x
Возможности платформы VMware vSphere 6.0:
Storage Policy Based Management (SPBM)
Thin Provisioning
Linked Clones
Native Snapshots
View Storage Accelerator also known as Content Based Read Cache (CBRC)
Storage vMotion
vSphere Flash Read Cache
Virtual SAN (VSAN)
vSphere Auto Deploy
High Availability (HA)
vMotion
xvMotion
vSphere Software Development Kit (SDK)
NFS version 3.x
Продукты и технологии, которые НЕ поддерживают Virtual Volumes (VVols):
Продукты VMware:
VMware vRealize Operations Manager 6.x
VMware vCloud Air
VMware Site Recovery Manager 5.x to 6.x
VMware vSphere Data Protection 5.x to 6.x
VMware Data Recovery 2.x
VMware vCloud Director 5.x
Возможности VMware vSphere 6.0:
Storage I/O Control
NFS version 4.1
IPv6
Storage Distributed Resource Scheduler (SDRS)
Fault Tolerance (FT) + SMP-FT
vSphere API for I/O Filtering (VAIO)
Array-based replication
Raw Device Mapping (RDM)
Microsoft Failover Clustering (MSCS)
Отслеживать официальную поддержку VVols со стороны продуктов и технологий VMware можно в специальной KB 2112039. Там же, кстати, находится и полезный FAQ.
Для поиска совместимого с технологией VVols оборудования необходимо использовать VMware Compatibility Guide:
Компания VMware еще с выходом VMware vSphere 5.1 объявила о нескольких новых начинаниях в сфере хранения данных виртуальных машин, включая возможность использования распределенного кеш на SSD-накопителях локальных дисков серверов ESXi. Данная технология имела рабочее название vFlash и находилась в стадии Tech Preview, превратившись позднее в полноценную функцию vSphere Flash Read Cache (vFRC) платформы VMware vSphere 5.5. И это вполне рабочий инструмент, который можно использовать в задачах различного уровня.
Вебинар пройдет 25 февраля в 19-00 по московскому времени.
На вебинаре Макс Коломейцев и Крис Эванс расскажут о новейших подходах к организации кэширования данных виртуальных машин на стороне сервера за счет использования Flash-накопителей и оперативной памяти, что вполне может быть альтернативой дорогостоящих All-Flash массивов с точки зрения производительности ввода-вывода.
На вебинаре будут рассмотрены следующие вопросы:
Принцип Парето (80/20) при распределении данных в областях памяти
Как работает кэширование на стороне сервера
Плюсы и минусы такого кэширования
Реализация кэширования в виртуальных средах (как в гостевой ОС, так и в хостовой)
Реализация кэширования в физических средах
Выбор правильного аппаратного обеспечения для хостов
Обзор возможностей программных продуктов различных вендоров
Вебинар, безусловно, получится очень интересным, особенно для тех, кто интересуется темой производительности виртуальной инфраструктуры.
Не так давно мы писали о новых возможностях решения для отказоустойчивости хранилищ VMware Virtual SAN 6.0, которое выйдет вместе с новой версией платформы виртуализации VMware vSphere 6. Одной из таких новых возможностей стал режим All-Flash Configuration, когда хост-сервер ESXi использует только SSD-накопители. При этом быстрые и надежные накопители используются для целей кэширования (cache tier), а устройства попроще - для хранения данных (capacity tier).
Чтобы использовать конфигурацию All-Flash нужно специальным образом пометить диски хост-серверов ESXi для яруса Capacity Tier. Сделать это можно через консоль RVC, либо через интерфейс ESXCLI на каждом из хостов.
Так, например, это делается через RVC:
А вот последовательность команд ESXCLI:
Получается, что на каждом из хостов кластера Virtual SAN администратор должен с помощью CLI-интерфейса обозначать диски, которые будут использоваться для создания яруса хранения виртуальных машин. Жутко неудобно.
Кстати, узнать о том, входит ли конкретный диск в Capacity Tier можно с помощью команды VSAN Disk Query (vdq):
# vdq -q
Так вот, коллеги с punchingclouds.com делают утилиту с GUI, которая позволит назначать дисковым устройствам на хостах ESXi это свойство быстро и удобно, экономя часы времени (представьте, что у вас 64 узла в кластере, на каждом из которых по 10 SSD-дисков, то есть надо назначить 640 дисков!).
Для начала работы надо ввести данные учетной записи VMware vCenter, а также пользователя на хостах VMware ESXi. Минус тут в том, что пароль на всех хостах должен быть одинаковый (но это обещают исправить в следующей версии, сделав загрузку csv-файла с паролями).
Перед тем, как приступить к операциям с дисками, нужно включить SSH на хостах ESXi (настройка на хостах происходит через ESXCLI), делается это кнопкой "Enable SSH". Далее можно сгруппировать похожие устройства по хостам или кластеру, после чего отметить нужные устройства в списке дисков.
Ну и далее нажимаем кнопку "Set Capacity Flash", чтобы назначить диски для хранения виртуальных машин, или "Remove Capacity Flash", чтобы отвязать их от этой роли.
Утилита VMware VSAN All-Flash Configuration Utility скоро будет доступна, следите за обновлениями здесь.
На днях сообщество Xen Project, разрабатывающее открытый гипервизор Xen под лицензией GNU General Public License (GPLv2), выпустило обновленную версию Xen Project Hypervisor 4.5.
Напомним, что разработка платформы виртуализации Xen поддерживается такими компаниями какAMD, Bitdefender, Cavium, Citrix, Fujitsu, GlobalLogic, Intel, Oracle и другими (так как многие из них встраивают Xen в свои платформы и продукты). Прошлая версия Xen 4.4 была выпущена в марте прошлого года.
Кстати, недавно мы писали о том, что компания Citrix выпустила продукт XenServer 6.5, который также построен на базе открытого Xen.
Новые возможности Xen 4.5:
Улучшения производительности. Режим виртуализации Xen PVH (паравиртуализация) теперь поддерживает исполнение в домене dom0 на Linux-платформах с процессорами Intel. Это позволяет использовать такие возможности аппаратной виртуализации как Virtual machine extensions (VMX) для снижения накладных расходов. И все это не требует ничего, кроме как поддержки на уровне гипервизора. Вместо того, чтобы постоянно обращаться к гипервизору, dom0 может выполнять операции нативно, без промежуточных уровней. Кроме того, увеличилась производительность механизма PCI passthrough.
Поддержка технологии Intel Resource Director Technology (RDT) и, в частности, техники Intel Cache Monitoring Technology (CMT) позволяет мониторить использование кэша Last Level Cache (LLC) трэдами приложений. Это позволяет проводить балансировку виртуальных ресурсов более эффективно.
Больше функций отказоустойчивости. Техника Coarse-grained Lock-stepping (COLO) позволяет реплицировать состояние первичной ВМ на другой хост в реальном времени (у VMware эта технология называется Fault Tolerance). Это было сделано на базе проекта Remus, который присутствовал в более ранних версиях гипервизора Xen.
Обновления для архитектуры ARM. Теперь поддерживается до 1 ТБ оперативной памяти для машин на базе этой архитектуры, а также техники super page mappings, irq migration и faster interrupt EOI. Также существенно был улучшен механизм работы с прерываниями и работа с UEFI.
Возможность "интроспекции" на уровне гипервизора. Фича HVM Guests Security предоставляет возможность защиты на уровне железа и гипервизора от эксплоитов, атак zero day, руткитов и других.
Обновления для автомобильных и внедренных систем - новый экспериментальный мультиядерный планировщик, позволяющий прогнозировать производительность ВМ.
Поддержка демона Systemd - позволяет избавиться от запланированных простоев в Linux-системах;
Более подробно о новых фичах гипервизора Xen 4.5 рассказано вот тут. Скачать Xen 4.5 можно по этой ссылке.
Таги: Xen, Update, Open Source, VMachines, Oracle, Citrix
Вчера компания Citrix объявила о выпуске обновленной версии своей серверной платформы виртуализации Citrix XenServer 6.5 (кодовое название Creedence). Напомним, что о новых возможностях этой версии мы писали еще в июле прошлого года (тогда еще предполагалось, что выйдет сразу версия 7.0).
Итак, новые возможности XenServer 6.5 (полный список тут, а Release Notes - вот тут):
64-битный домен dom0 (то есть, теперь все 64-битное)
Новая версия ядра Linux 3.10
Гипервизор Xen версии 4.4
Функции Workload balancing (WLB), предоставляемые отдельным виртуальным модулем WLB appliance
Обновленный виртуальный коммутатор Open virtual switch 2.1.x
Вслед за обновлением продуктов семейства vRealize, компания VMware выпустила обновленную версию своего решения для управления образами ПК предприятия - VMware Mirage 5.2. О возможностях версии VMware Mirage 5.1, которая вышла три месяца назад, мы писали тут.
Напомним, что решение VMware Mirage позволяет создать образ рабочей станции пользователя, разделив его на слои (система, приложения, а также данные и настройки пользователя), а потом централизованно управлять такими образами и деплоить их на конечные физические и виртуальные ПК (подробно мы писали об этом тут).
Продукт VMware Mirage теперь является частью решения VMware Horizon FLEX - средства управления локальными виртуальными ПК, их операционной системой, данными и приложениями.
Итак, новые возможности VMware Mirage 5.2:
Mirage может быть использован с виртуальными машинами FLEX (локальные ВМ). Более подробно об этом можно почитать вот тут. Теперь можно управлять образами ОС, данными пользователей и приложениями централизованно из консоли Mirage.
Поддержка POS-устройств (point of sale или по-другому point of service). В Mirage 5.2 поддерживается миграция Windows Embedded POS на POSReady2009.
Администраторы могут указывать дисковые устройства, включая несистемные, для использования компонента branch reflector cache. Новый аларм CVD оповещает администратора, когда этот кэш становится недоступен.
Полная поддержка VSS в Windows 7, Windows 8 и Windows 8.1, что делает операции загрузки компонентов пользовательского окружения более эффективными.
Администраторы могут использовать командлеты Mirage PowerCLI в Microsoft PowerShell.
Улучшена функциональность веб-отчетов:
Экспорт отчетов в форма XLS.
Возможность указания времени генерации отчета и диапазона времени для выборки данных.
Переименование шаблонов отчетов.
Удаление шаблона отчета не приводит к удалению отчетов, созданных на его базе.
В представлении шаблонов отчета показывается интервал запланированного запуска и иконка типа отчета.
Администраторы могут вручную сменить IP-адрес для сервера Mirage Gateway через консоль Mirage Management.
С развитием ИТ инфраструктуры организации нередко приходят к идее перевода физических рабочих станций в виртуальную среду VDI (Virtual Desktop Infrastructure), т.к. это позволяет более эффективно и гибко использовать имеющиеся ресурсы, а так же быстро реагировать на возникающие потребности. При этом приходится решать ряд вопросов, на которые ранее обращалось мало внимания. Большинство из них связано с нагрузками, возникающими при одновременном выполнении действий на большом количестве виртуальных машин. Но есть и вопросы, связанные со способом создания и управления жизненным циклом машин...
Некоторое время назад мы писали о технологии VMware vFlash (она же Virtual Flash), которая позволяет использовать высокопроизводительные накопители SSD (вот тут - о производительности) для решения двух важных задач:
Предоставление виртуальным машинам дополнительного места, в которое будут свопиться страницы памяти в случае недостатка ресурсов на хосте (это намного более производительно, чем свопить на обычный HDD-диск). Эта техника называется Virtual Flash Host Swap и пришла на смену механизму Swap to SSD.
Прозрачное встраивание в поток ввода-вывода на хосте между виртуальными машинами и хранилищами, что позволяет существенно ускорить операции чтения данных виртуальных дисков. Называется это VMware Flash Read Cache (vFRC).
Ниже мы вкратце расскажем о настройке этих двух механизмов через VMware vSphere Web Client (в обычном C#-клиенте этого, к сожалению, нет). Если что, более подробно о технике vFRC можно почитать по этой ссылке.
Итак, в vSphere Web Client переходим на вкладку "Manage" для нужного хоста, далее в разделе "Settings" выбираем пункт "Virtual Flash Resource Management". Это кэш, который мы добавляем для того, чтобы в случае нехватки места, его могли использовать виртуальные машины, чтобы не свопить данные на медленный магнитный диск, кроме того он же будет использоваться для целей vFRC.
Нажимаем Add Capacity:
Выбираем диски, которые мы будем использовать как Host Swap и нажимаем "Ок" (все данные на них будут стерты):
Всего под нужды Virtual Flash может быть выделено до 8 дисков суммарной емкостью до 32 ТБ. Видим, что ресурс добавлен как Virtual Flash Resource (его емкость отдельно учитывается для vFRC и Host Cache):
Настройка Virtual Flash Host Swap
Первым делом рекомендуется настроить именно этот кэш, а остаток уже распределять по виртуальным машинам для vFRC.
Выбираем пункт "Virtual Flash Host Swap Cache Configuration" в левом меню, а далее в правой части мы нажимаем кнопку "Edit":
Указываем необходимый объем, который планируется использовать, и нажимаем "Ок":
После того, как мы настроили нужное значение - в случае недостатка ресурсов на хосте виртуальные машины будут использовать высокоскоростные диски SDD для своих нужд внутри гостевой ОС (файлы подкачки прочее).
Настройка VMware Flash Read Cache (vFRC)
Напомним, что это кэш только на чтение данных, операции записи будут производиться на диск, минуя флэш-накопители. Соответственно, такой кэш улучшает производительность только операций чтения.
Сам кэш vFRC можно настроить на уровне отдельных виртуальных машин на хосте VMware ESXi, а также на уровне отдельных виртуальных дисков VMDK.
Чтобы выставить использование нужного объема vFRC для отдельной виртуальной машины, нужно выбрать пункт "Edit Settings" из контекстного меню ВМ и на вкладке "Virtual Hardware" в разделе "Virtual Flash Read Cache" установить нужное значение для соответствующего виртуального диска:
Если этого пункта у вас нет, то значит у вас версия виртуального "железа" (Virtual Machine Hardware) ниже, чем 10, и ее нужно обновить.
По ссылке "Advanced" можно настроить размер блока для кэша (значение Reservation, установленное тут, обновит значение на предыдущем скрине):
Не секрет, что на рынке для создания отказоустойчивых программных хранилищ для виртуальных машин есть два лидера - это StarWind Virtual SAN (о котором мы часто пишем) и VMware Virtual SAN (продукт компании VMware для своей платформы vSphere).
В таблице ниже мы решили показать, почему StarWind Virtual SAN во многом лучше VMware Virtual SAN, рассмотрев значимые для администраторов технические критерии выбора продукта. Конечно же, это не все критерии и по каким-то параметрам Virtual SAN от VMware будет работать лучше, кроме того продукты представляют собой различные архитектуры построения отказоустойчивых кластеров, но тем не менее в каком-то ракурсе сравнить их все-таки можно.
Итак:
Критерий сравнения
StarWind Virtual SAN
VMware Virtual SAN
Минимальное число узлов кластера
2
3
Максимальное число узлов
Не ограничено (разные кластеры)
32 (один кластер)
Максимальная емкость кластеров
Не ограничена (разные кластеры)
148 ТБ (один кластер)
Наличие Flash-накопителей (SSD)
Не требуется
Обязательно
Тип RAID
Любой
Только 5, 10
Наличие коммутатора 10G
Не обязательно
Обязательно
Технология дедупликации
Встроенная (in-line)
Отсутствует
Поддержка создания кластеров хранилищ для ВМ Hyper-V
Да
Нет
Кэш
В памяти (WB or WT) или Flash cache
Только Flash cache
Более подробно о новых возможностях восьмой версии StarWind Virtual SAN можно узнать вот тут, а тут доступен документ со сравнением платного и бесплатного изданий продукта.
Таги: StarWind, Virtual SAN, Сравнение, VMware, vSphere, Storage, HA, iSCSI
ИТ-ГРАД запускает новую облачную площадку в дата-центре SDN. Перед переводом площадки в промышленную эксплуатацию мы должны убедиться в том, что все ее компоненты работают как задумывалось, а дублирование и обработка аппаратных сбоев происходит в штатном режиме. Для проверки работоспособности новой облачной площадки был разработан план тестирования, с которым вам и предлагаем ознакомиться.
Немного о наполнении новой площадки:
На первом этапе в новый ЦОД была установлена система хранения данных NetApp FAS8040 (мы как золотой партнер компании NetApp – остаемся верны вендору), система пока имеет 2 контроллера FAS8040, которые собраны в кластер через дублируемые 10Gbit/s коммутаторы (Cluster Interconnects) и позволяют наращивать кластер СХД до 24 контроллеров. Контроллеры СХД в свою очередь подключены к сети ядру сети по 10Gbit/s оптическим линкам сформированое двумя коммутаторами Cisco Nexus 5548UP с поддержкой L3.
Серверы гипервизоров VMware vSphere ESXi (Dell r620/r820) подключаются к сети по двум интерфейсам 10Gbit/s, используя конвергентную среду передачи данных (для работы с дисковым массивом и сетью передачи данных). Пул ESXi серверов образует кластер с поддержкой VMware vSphere High Availability (HA). Менеджмент интерфейсы серверов iDRAC и контроллеров СХД собираются на отдельном выделенном коммутаторе Cisco.
Когда базовая настройка инфраструктуры фактически была завершена настало время остановиться и оглядеться назад: ничего не забыли? все ли работает? надежно?
Задел на успех в лице опытных инженеров мы уже имеем, но чтобы «фундамент» оставался крепким, необходимо, конечно же, правильно провести испытания на стрессоустойчивость инфраструктуры. Успешное окончание тестов будет свидетельствовать о завершении первого этапа и сдачи приемо-сдаточных испытаний (ПСИ) новой облачной площадки.
Итак, озвучу «исходные данные» и «план тестирования». А внимательные читатели, которым не чужда судьба ИТ-ГРАДа, могут внести предложения/рекомендации/пожелания возможных моментов, которые мы могли не предусмотреть. С радостью их выслушаем.
«Исходные данные»:
FAS8040 dual controller под управлением Data ONTAP Release 8.2.1 Cluster-Mode
Коммутаторы ядра унифицированной сети Cisco Nexus 5548 – 2 шт.
Пограничный роутер Juniper MX80 (пока один, второй ещё не приехал).
Управляемый коммутатор Cisco 2960.
Серверы Dell PowerEdge R620/R810 with VMware vSphere ESXi 5.5.
Схема подключения выглядит следующим образом:
Нарочно не стал рисовать менеджмент свитч и Juniper MX80, т.к. связность интернет будем тестировать после резервирования канала, не хватает ещё одного Juniper MX80 (ждем к концу месяца).
Итак, условно наши «краш-тесты» можно поделить на 3 вида:
Тестирование дискового массива FAS8040;
Тестирование сетевой инфраструктуры;
Тестирование виртуальной инфраструктуры.
При этом тестирование сетевой инфраструктуры в нашем случае выполняется в укороченном варианте по причинам, которые я указывал выше.
Перед тестами планируется ещё раз сделать бэкапы конфигураций сетевого оборудования и массива, а также проанализировать результаты дискового массива с помощью Config Advisor.
Теперь давайте расскажу подробнее о плане тестирования.
I. Удаленное тестирование
Поочередное выключение контроллеров FAS8040.
Ожидаемый результат: автоматический takeover на рабочую ноду, все ресурсы VSM должны быть доступны на ESXi, доступ к датасторам не должен пропадать.
Поочередное отключение всех Cluster Link одной ноды.
Ожидаемый результат: автоматический takeover на рабочую ноду, либо перемещение/переключение VSM на доступные сетевые порты на второй ноде, все ресурсы VSM должны быть доступны на ESXi, доступ к датасторам не должен пропадать.
Отключение всех Inter Switch Link между свичами CN1610.
Ожидаемый результат: предполагаем, что кластерные ноды будут доступны друг для друга через cluster links одного из Cluster Interconnect (в связи с перекрестным соединением NetApp — Cluster Interconnect).
Перезагрузка одного из Nexus.
Ожидаемый результат: один из портов на нодах должен оставаться доступным, на IFGRP интерфейсах на каждой ноде должен оставаться доступен один из 10 GbE интерфейсов, все ресурсы VSM должны быть доступны на ESXi, доступ к датасторам не должен пропадать.
Поочередное гашение одного из vPC (vPC-1 или vPC-2) на Nexus.
Ожидаемый результат: перемещение/переключение VSM на доступные сетевые порты на второй ноде, все ресурсы VSM должны быть доступны на ESXi, доступ к датасторам не должен пропадать.
Поочередное отключение Inter Switch Link между коммутаторами Cisco Nexus 5548.
Ожидаемый результат: Port Channel активен на одном линке, нет потери связности между коммутаторами.
Поочередное жесткое отключение ESXi.
Ожидаемый результат: отработка HA, автоматический запуск ВМ на соседнем хосте.
Слежение за отработкой мониторинга.
Ожидаемый результат: получение нотификаций от оборудования и виртуальной инфраструктуры о появившихся проблемах.
II. Непосредственно на стороне оборудования
Отключение кабелей питания (все единицы оборудования).
Ожидаемый результат: оборудование работает на втором блоке питания, нет проблем с переключением между блоками.
Замечание: Менеджмент свитч Cisco не имеет резервирования питания.
Поочередное отключение сетевых линков от ESXi (Dell r620/r810).
Ожидаемый результат: ESXi доступен по второму линку.
Не так давно мы писали о новых возможностях лидирующей на рынке платформы виртуализации VMware vSphere 6, которая на данный момент доступна в публичной бета-версии.
Одной из новых возможностей был заявлен механизм vSphere APIs for IO Filtering (VAIO - как ноутбуки от Sony), который позволяет получать прямой доступ к потоку ввода-вывода (I/O Stream) гостевой ОС виртуальной машины. Несмотря на то, что об этой штуке писали достаточно мало, механизм VAIO в будущем будет способствовать созданию множества партнерских продуктов для решения самых разнообразных задач. VAIO основан на механике Storage Policy Based Management (SPBM), которая предназначения для управления хранением виртуальных машин.
Техническая реализация данного механизмв подразумевает использование драйвера VAIO (filter driver), который устанавливается на хосте VMware ESXi как пакет VIB и не требует установки никакого специального ПО в гостевой ОС виртуальной машины. Работает он на уровне VMDK-диска отдельной ВМ и позволяет не только получать данные из потока ввода-вывода, но и изменять его при течении данных в ту или другую сторону.
Это открывает возможности для применения VMware VAIO при решении следующих типов задач:
Encryption – стороннее ПО за счет использования механизма VAIO может на лету шифровать и расшифровывать поток данных от виртуальной машины. Таким образом на хранилище будут помещаться уже шифрованные данные. Гранулярность работы VAIO позволяет обслуживать данные идущие даже не от всей виртуальной машины, а только от одного приложения.
De-duplication - этот механизм уже использует решение VMware Virtual SAN. В реальном времени можно дедуплицировать данные, проходящие через драйвер и в таком виде уже класть на хранилище в целях экономии дискового пространства. Теперь это станет доступно и партнерам VMware.
Tiering - данные различной степени важности, критичности или классифицированные по другим критериям теперь можно класть на хранилища с разными характеристиками производительности и доступности (ярусы). Механизм VAIO тут поможет проанализировать характер данных и определить конечное их место назначения.
Analytics - теперь можно анализировать непосредственно поток данных от конкретной виртуальной машины и на основе этого строить множество различных решений, включая решения по кэшированию (например, такой продукт как CahceBox можно будет напрямую подключить к гипервизору). Затем можно, например, искать в трафике данные определенных приложений, либо, например, использовать механизм write-back кэширования.
На первом этапе запуска технологии VAIO компания VMware решила остановиться на двух путях ее имплементации:
1. Возможности кэширования данных на SSD-накопителях (write-back кэширование для операций записи). Дизайн-документ для API тут делала компания SanDisk, которая первой будет использовать VAIO в своих продуктах. Вот их презентация:
А вот технология write-back кэширования на стороне сервера с использованием механизма VAIO:
2. Возможности высокопроизводительной репликации. Реализация данного аспекта VAIO позволит получать прямой доступ к потоку ввода-вывода и сразу же передавать его на другой хост, не прибегая к дополнительным механизмам, которые сегодня используются для реализации техник репликации. На данный момент заявлено, что такой тип репликации будет поддерживать ПО EMC RecoverPoint, команда которого принимала участие в разработке техники VAIO.
Однако несмотря на все плюсы технологии vSphere APIs for IO Filtering, в ней есть и негативные стороны:
Во-первых, это вопрос надежности. Так как между виртуальной машиной и хранилищем есть дополнительное звено, которое может рухнуть, понижается и совокупная надежность платформы виртуализации.
Во-вторых, это вопрос производительности. Прослушка трафика посредством VAIO неизбежно создает нагрузку на аппаратные ресурсы хоста ESXi.
В-третьих, это вопрос безопасности. Представим, что я написал софт, который прозрачно шифрует и расшифровывает трафик отдельной виртуальной машины на хосте ESXi, после чего внедрил его в инфраструктуру предприятия, где все это произошло незаметно для пользователей и администраторов. Затем я просто убираю это ПО из гипервизора (например, при увольнении), после чего данные на хранилищах превращаются в тыкву, а компания сталкивается с серьезной проблемой.
В целом же, подход VMware в данном вопросе очень радует - она открывает партнерам возможности разработки собственных продуктов для решения задач пользователей, а значит предоставляет и неплохую возможность заработать.
Первые реализации механизма vSphere APIs for IO Filtering мы должны увидеть уже в первой половине 2015 года, когда выйдет обновленная версия платформы VMware vSphere 6.
Компания StarWind Software, производитель средства номер один для создания отказоустойчивых кластеров StarWind Virtual SAN, недавно обновила свою библиотеку открытых документов, касающихся технических аспектов решения.
Также рекомендую заглянуть в раздел Technical Papers, где для новичков будет очень полезен Quick Start Guide по StarWind Virtual SAN. Все качается по прямым ссылкам и без регистрации.
Symantec Endpoint Protection 12.1 представляет из себя корпоративное решение по защите конечных точек от различных угроз: вирусов, сетевых атак и атак нулевого дня. В состав технологий защиты входят антивирус, сетевой экран, система предотвращения вторжений, контроль устройств и контроль приложений. Одной из ключевых особенностей решения является...
Это гостевой пост компании ИТ-ГРАД - облачного провайдера инфраструктур VMware vSphere.
Мне давно не попадался на тесты массив начального уровня, способный пропустить через один контроллер до 1.5 Гб/сек при потоковой нагрузке. NetApp E2700 как раз справился с этой задачей. В июне я провёл Unboxing NetApp E2700. И теперь готов поделиться с вами результатами тестирования этой системы хранения данных. Ниже привожу результаты нагрузочных тестов и получившиеся количественные показатели производительности массива NetApp E-Series 2700 (IOps, Throughput, Latency).
Некоторое время назад компания VMware выпустила интересный документ "Understanding Data Locality in VMware Virtual SAN", касающийся локальности данных, то есть механизмов соблюдения временных и пространственных характеристик правильного чтения данных в целях оптимизации производительности кластера хранилищ Virtual SAN.
Мысль тут такая: локальность данных бывает двух типов:
временная (Temporal locality) - это когда есть вероятность, что данные, использованные сейчас, потребуются снова в ближайшее время (это актуально, поскольку в инфраструктуре виртуализации несколько машин на хосте часто используют одни и те же данные).
пространственная (Spatial locality) - ситуация, когда есть вероятность, что после чтения некоторой области данных потребуется прочитать и данные находящиеся рядом - то есть в соседних блоках на хранилище.
Так вот, в документе подробно разбирается, каким именно образом обеспечивается работа с этими особенностями локальности данных применительно к кэшированию данных на хранилищах SSD хостов VMware ESXi.
Примерами работы с локальностью данных являются следующие особенности кластеров Virtual SAN:
Каждый раз, когда виртуальная машина читает данные с хранилища, они сохраняются в кэше (Read Cache) на SSD-накопителе и эти данные могут быть востребованы очень быстро. Это работа с Temporal locality.
С точки зрения Spatial locality, при кэшировании данных в кэш сохраняется также и "окрестность" этих данных в рамках чанков по 1 МБ.
Virtual SAN имеет адаптивный алгоритм по вытеснению и сохранению данных в кэше - если данные используются редко, они выпадают с SSD-накопителя, а часто востребованные данные будут находиться там постоянно.
Virtual SAN распределяет экземпляры данных по разным хост-серверам ESXi и работает при чтении сразу с несколькими узлами, но при чтении одного диапазона логических адресов работа идет только с одной репликой. Обусловлено это двумя фактораи: во-первых, увеличивается шанс того, что читаемые данные уже находятся в кэше на SSD, а значит будут прочитаны быстрее, ну и, во-вторых, один блок данных всегда будет закэширован только на одном узле, а значит дорогое SSD-пространство не будет пожираться дубликатами блоков.
В общем документ очень интересный - почитайте. Там еще много полезной информации на эту тему.
Помимо всего прочего, в документе рассматривается способ получения информации о структуре и содержимом кэша vFRC. Сделать это можно с помощью команды:
~ # esxcli storage vflash cache list
Эта команда выведет список идентификаторов кэша для VMDK-дисков, для которых включена vFRC. Далее с помощью следующей команды можно узнать детали конкретного ID кэша:
# esxcli storage vflash cache get –c <cache-identifier>
Несколько больше информации (включая объем закэшированных данных) можно почерпнуть из команд, приведенных ниже. Для этого потребуется создать переменную CacheID:
~ # cacheID='vsish -e ls /vmkModules/vflash/module/vfc/cache/'
~ # vsish -e get /vmkModules/vflash/module/vfc/cache/${cacheID}stats
В результате будет выведено что-то подобное:
vFlash per cache instance statistics {
cacheBlockSize:8192
numBlocks:1270976
numBlocksCurrentlyCached:222255
numFailedPrimaryIOs:0
numFailedCacheIOs:0
avgNumBlocksOnCache:172494
read:vFlash per I/O type Statistics {
numIOs:168016
avgNumIOPs:61
maxNumIOPs:1969
avgNumKBs:42143
maxNumKBs:227891
avgLatencyUS:16201
maxLatencyUS:41070
numPrimaryIOs:11442
numCacheIOs:156574
avgCacheLatencyUS:17130
avgPrimaryLatencyUS:239961
cacheHitPercentage:94
}
write:vFlash per I/O type Statistics {
numIOs:102264
avgNumIOPs:307
maxNumIOPs:3982
avgNumKBs:10424
maxNumKBs:12106
avgLatencyUS:3248
maxLatencyUS:31798
numPrimaryIOs:102264
numCacheIOs:0
avgCacheLatencyUS:0
avgPrimaryLatencyUS:3248
cacheHitPercentage:0
}
rwTotal:vFlash per I/O type Statistics {
numIOs:270280
avgNumIOPs:88
maxNumIOPs:2027
avgNumKBs:52568
maxNumKBs:233584
avgLatencyUS:11300
maxLatencyUS:40029
numPrimaryIOs:113706
numCacheIOs:156574
avgCacheLatencyUS:17130
avgPrimaryLatencyUS:27068
cacheHitPercentage:58
}
flush:vFlash per operation type statistics {
lastOpTimeUS:0
numBlocksLastOp:0
nextOpTimeUS:0
numBlocksNextOp:0
avgNumBlocksPerOp:0
}
evict:vFlash per operation type statistics {
lastOpTimeUS:0
numBlocksLastOp:0
nextOpTimeUS:0
numBlocksNextOp:0
avgNumBlocksPerOp:0
}
}
Приведенный вывод содержит все метрики, означенные в упомянутом документе. Далее вы можете использовать эту информацию для принятия решения о размере кэша на серверах ESXi и значении других настроек, описанных в документе.
Использование Read caching для репозиториев хранилищ файлового типа
Использование техник TRIM и UNMAP для возврата дисковых емкостей на сторону хранилищ при удалении виртуальных машин
Миграция виртуальных машин с 32-битной платформы на 64-битную
Технология миграции хранилищ с XenServer 6.2 и более ранних
Поддержка гостевой ОС SLES 11 SP3
Поддержка гостевой ОС Ubuntu 14.04 LTS
По поводу обработки эффекта Boot storm в Citrix добились внушительных результатов. На рисунке ниже представлен график зависимости времени загрузки виртуальной машины от числа одновременно запускаемых ВМ на хосте. Зеленый график отражает время загрузки с использованием улучшений по кэшированию на чтение, а красный - это то, что было раньше:
Скачать новую версию XenServer можно по этим ссылкам:
Те из вас, кто интересуется VDI-инфраструктурой, знают про калькулятор VDI Calculator (последний раз мы писали о нем тут), который разрабатывает Andre Leibovici, автор сайта myvirtualcloud.net. Сегодня это калькулятор номер 1 для расчета параметров инфраструктуры виртуальных ПК на базе VMware View и Citrix XenDesktop - он позволит ответить на такие вопросы как: сколько серверов нужно для построения инфраструктуры виртуальных ПК, какие у них должны быть аппаратные характеристики, сколько дисковых емкостей нужно для размещения ВМ и т.п.
На днях Андрэ выпустил шестую версию своего калькулятора, в которой появилось несколько интересных новых возможностей.
Итак, новые возможности VDI Calculator v6.0:
Horizon View and XenDesktop Infrastructure Calculation - если раньше калькулятор просто рассчитывал необходимое количество серверов View Connection и Security, либо XenDesktop Controller, то теперь он позволяет конкретно получить информацию о том, сколько вычислительных ресурсов потребуется для размещения управляющих компонентов инфраструктуры. Для этого нужно выбрать опцию "Backend Infrastructure".
Java Code Signing - теперь код продукта подписан и не вызывает консёрна пользователей при его запуске.
Write Cache Sizing - когда вы используете опцию сайзинга для десктопов типа Horizon View Linked Clones или XenDesktop MCS, то калькулятор определяет размер дельты и кэша. Можно указать свои значения, если у вас есть собственная методика их расчета. Это позволит получить более корректные данные по целевой инфраструктуре.
Публикуем очередной гостевой пост компании ИТ-ГРАД. Никто не скажет лучше про продукт, чем пиарщики его вендора. Поэтому мы просто процитируем одну из брошюр NetApp о новоиспеченной E2700 серии: СХД NetApp E2700 представляет собой простое решение для хранения данных в средах SAN. Она легко интегрируется практически в любые среды хранения данных, основанные на приложениях, предлагает множество вариантов хостингового подключения и поддерживает различные типы дисков и дисковых полок...

 RSS
RSS
































































{kind=link}

